GPU 系列 - 1. GPU 的两种同步方式
GPU 系列 (Pytorch) - 1. GPU 的两种同步方式
0. pytorch 不同版本的安装
在开始说明 pytorch 不同版本的安装
在 pytorch 的官网查看安装指导 - GPU 安装 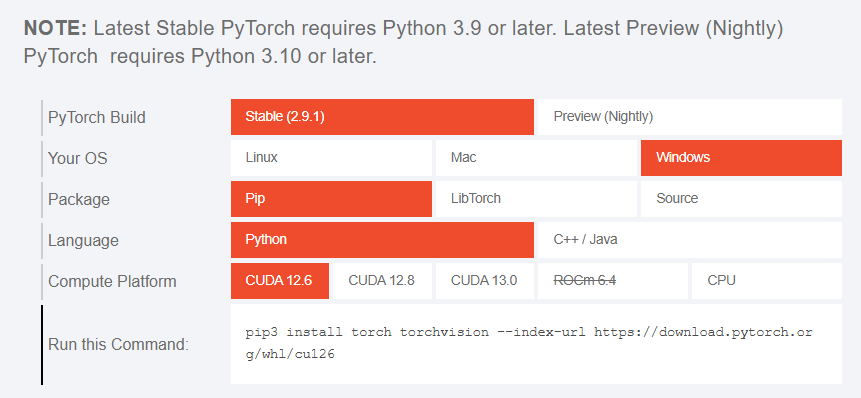 - CPU 安装
- CPU 安装 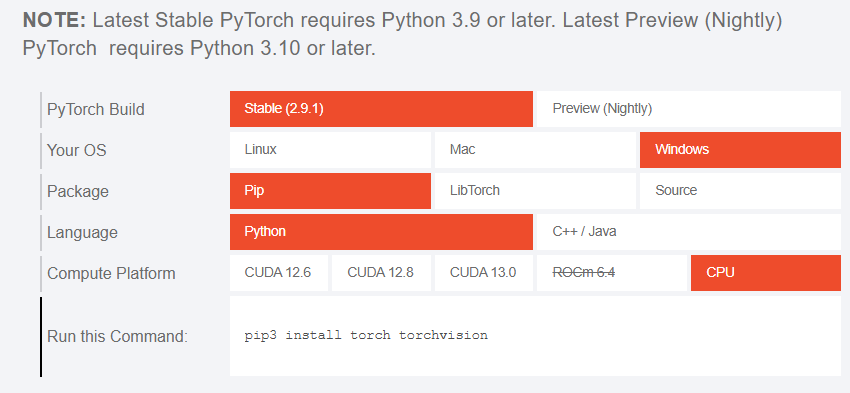
关于 GPU 的常见误区
- ❌“有 GPU 就一定更快”:小任务/小 batch/频繁传输时未必。
- ❌“提速只能靠换卡”:数据加载、批量、传输模式、算子融合,往往是更便宜的提升空间。
接下来通过几个例子初步认识一下 GPU 的运行机制
1. GPU 的预热现象
例1 进行两次 GPU 乘法计算,分别查看耗时(注意,其实这里统计的时间,不是 GPU 计算乘法真正耗时) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import torch, time
N = 4000
# case1:GPU 乘法计算
a1 = torch.randn(N, N, device="cuda")
b1 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c1 = a1 @ b1 # GPU:第 1 次执行乘法
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")
# case2:GPU 乘法计算
a2 = torch.randn(N, N, device="cuda")
b2 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c2 = a2 @ b2 # GPU:第 2 次执行乘法
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")1
2[GPU] 耗时: 0.077134s
[GPU] 耗时: 0.001915s
第 1 次计算是“冷启动”
第 2 次计算是“热身后”
第 1 次 GPU 计算耗时 >> 第 2 次 GPU 计算耗时
2. GPU 的预热耗时
例2 进行两次 GPU 乘法计算,分别查看耗时(注意,其实这里统计的时间,不是 GPU 计算乘法真正耗时) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import torch, time
N = 4
# case1:GPU 乘法计算
a1 = torch.randn(N, N, device="cuda")
b1 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c1 = a1 @ b1 # GPU:第 1 次执行乘法
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")
# case2:GPU 乘法计算
a2 = torch.randn(N, N, device="cuda")
b2 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c2 = a2 @ b2 # GPU:第 2 次执行乘法
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")1
2[GPU] 耗时: 0.078570s
[GPU] 耗时: 0.000069s
3. GPU 的异步工作方式
例3 使用 CPU 和 GPU 进行乘法计算,分别查看耗时(注意,其实这里统计 GPU 工作时间有两种方式,第二种更科学) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import torch, time
N = 4000
# Case1: CPU 第一次计算
a1 = torch.randn(N, N)
b1 = torch.randn(N, N)
t0 = time.perf_counter()
c1 = a1 @ b1 # CPU:调用会一直等到乘法真正算完才返回
t1 = time.perf_counter()
print(f"[CPU] 耗时: {t1 - t0:.6f}s")
# Case2: CPU 第二次计算
a2 = torch.randn(N, N)
b2 = torch.randn(N, N)
t0 = time.perf_counter()
c2 = a2 @ b2 # CPU:调用会一直等到乘法真正算完才返回
t1 = time.perf_counter()
print(f"[CPU] 耗时: {t1 - t0:.6f}s")
# Case3: GPU(预热计时)
a3 = torch.randn(N, N, device="cuda")
b3 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c3 = a3 @ b3 # GPU:只是把任务放进队列,立即返回
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")
# case4:GPU(错误计时示范)
a4 = torch.randn(N, N, device="cuda")
b4 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c4 = a4 @ b4 # GPU:只是把任务放进队列,立即返回
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")
# case5:GPU(正确计时示范)
a5 = torch.randn(N, N, device="cuda")
b5 = torch.randn(N, N, device="cuda")
t0 = time.perf_counter()
c5 = a5 @ b5 # GPU:只是把任务放进队列,立即返回
torch.cuda.synchronize() # 【强制同步】等待GPU完成!
t1 = time.perf_counter()
print(f"[GPU] 耗时: {t1 - t0:.6f}s")
\(N = 4000\),执行得到以下结果: 1
2
3
4
5[CPU] 耗时: 0.149812s
[CPU] 耗时: 0.119700s
[GPU] 耗时: 0.077278s
[GPU] 耗时: 0.001844s
[GPU] 耗时: 0.027026s1
2
3
4
5[CPU] 耗时: 0.000254s
[CPU] 耗时: 0.000051s
[GPU] 耗时: 0.079781s
[GPU] 耗时: 0.000082s
[GPU] 耗时: 0.000241s
Case 1 vs 4 vs 5 对应的运行机制如下
1 | |
4. GPU 两种同步方式
例4 考虑以下两种 GPU 同步方式
1 | |
执行后结果 1
2
3[GPU] 预热耗时: 0.083418s
[GPU] 同步1耗时: 0.013568s
[GPU] 同步2耗时: 0.005645s
两种同步方式的机制如下图所示
1 | |